
October 30, 2024
The Data Lineage Apache Flink Really Needs: Debugging Policy Violations
Last week at Flink Forward, together with Colten Pilgreen, I had the pleasure of presenting Datorios’ data lineage



In the ever growing world of data processing, where information moves rapidly through intricate systems, understanding the path your data takes is no small feat. This is where data lineage comes into play! Think of data lineage as the blueprint of your Flink pipeline, showing how data is transformed and passed between different operators. This knowledge is invaluable for troubleshooting issues, ensuring compliance, and optimizing performance. However, data lineage in Flink is a very broad topic and it can encompass an entire view of your organization, but in this article, we’re going to zoom in a bit and explore the significance of data lineage. We’ll see how it can be effectively traced and we’ll talk about the applications of lineage within your Flink pipelines.
Data lineage refers to the life cycle and journey of your data as it moves from the sources to various transformations, and finally to the sink. In the context of Flink, this involves tracking how data flows between different operators (such as maps, filters, process functions, and windows) and understanding the transformations that data undergoes at each step. This information is crucial for several reasons:
I’ll let you in on a little secret, the “blueprint” that we were imaging earlier, we actually get it for free when we use Flink. You may know this blueprint as the Job Graph, and it’s your key to understanding data lineage. This graph is generated when you define your Flink job, mapping out the relationships between operators like map, filter, window, and sink. The Job Graph is a Directed Acyclic Graph (DAG), which means it flows in one direction without any loops – perfect for tracing the path your data takes through the pipeline.
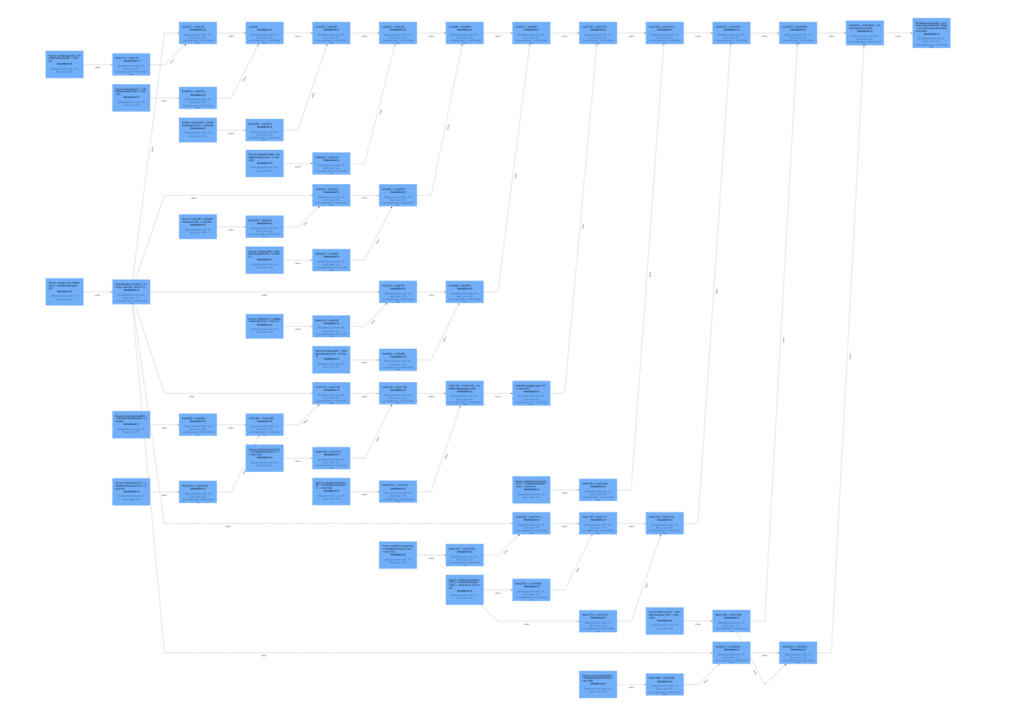
Each node in the Job Graph represents an operator/task, and the edges between them depict the flow of data. This graph not only shows how operators are connected but also offers insights into how data is partitioned, shuffled, and distributed across the pipeline. By analyzing this graph, you can trace the lineage of data as it moves from its source, undergoes various transformations, and finally reaches its sink.
In Flink, each operation on a DataStream generates a new logical node in the execution graph. This graph can be analyzed to understand the lineage of data as it passes through the operators. For instance:
By examining the input and output relationships between these operators, one can construct a lineage graph that represents the flow of data through the pipeline. This can help work out which sources could have provided data to downstream consumers and, vice versa, where your data could end up once it has entered the pipeline.
Flink provides an execution plan that details how the system translates logical operators into physical execution tasks. You can visualize and analyze this plan to understand data lineage. The execution plan shows how data partitions, shuffles, and distributes across various nodes in the cluster.
State is a critical aspect of stream processing in Flink. Each operator can maintain state values that track records across different events. Understanding how state is managed and checkpointed across operators is vital for maintaining accurate lineage. Stateful operators could make tracing lineage for individual records even trickier due to the fact that a record could be held in state for long periods of time before they’re transformed and sent further downstream.
Understanding data lineage isn’t just a theoretical exercise, it also has real-world applications that can significantly enhance the way you work with Flink.
When something goes wrong in a Flink job, whether it’s data corruption, unexpected outputs, or a performance bottleneck, knowing the lineage of your data can make debugging much simpler. By tracing the data flow through the Job Graph and execution plan, you can pinpoint where things started to go awry and address the issue more efficiently.
In many industries, regulatory compliance is critical, and data lineage plays a vital role in ensuring that your data processing meets legal standards. By maintaining a clear record of how data is transformed and moved within your Flink jobs, you can provide the necessary transparency to auditors and regulators. This can be crucial for proving the integrity and accuracy of your data processing workflows.
Data lineage can also help you optimize your Flink jobs. By understanding how data flows through the pipeline, you might discover opportunities to streamline operations, reduce data shuffling, or improve resource allocation. For example, if you notice that a certain join operation is a bottleneck, you could explore alternative strategies, such as using broadcast joins or optimizing the partitioning scheme.
Tracking data lineage in Flink can be approached in various ways, depending on your specific needs and the complexity of your pipelines.
You didn’t think it was going to be all rainbows and sunshine did you? Of course not! These are some of the major challenges that you may face on your journey into data lineage.
Data lineage in an Apache Flink pipeline is much more than a technical curiosity—it’s an essential tool for ensuring the reliability, performance, and compliance of your data processing workflows. By tracing the journey of data through various operators and understanding the transformations it undergoes, you gain powerful insights that can make your Flink pipelines more robust and efficient.
As data processing environments continue to grow in complexity, having a detailed understanding of your data’s lineage will become increasingly vital. With the right tools and strategies in place, you can ensure that your Flink pipelines are not only operationally sound but also transparent, accountable, and optimized for the challenges of tomorrow.
Until next time! 👋🏻
Last week at Flink Forward, together with Colten Pilgreen, I had the pleasure of presenting Datorios’ data lineage

Introduction At Datorios, we are always pushing boundaries to empower real-time data processing at scale. Today, we are


Apache Flink is a powerful, open-source stream processing framework for real-time and batch data processing. Flink-as-a-Service operations provide
Fill out the short form below