Observability and data lineage are essential parts of mission-critical software systems. It provides insights into software execution that help teams troubleshoot errors, audit compliance with regulatory standards, investigate security vulnerabilities, and more.
The Three Pillars of Observability
Observability systems traditionally comprise three key pillars: logs, metrics, and traces. These pillars are required to help people understand system performance and behavior:
Logs are time-stamped records of system events (such as a file deletion, an execution error, or database login).
Metrics are system performance data points such as CPU usage percentage, memory consumption, client request rates, and other statistics that provide an overview of system health over time.
Traces record the execution of specific program steps, providing an end-to-end view application flow and interactions.
Each of the pillars provides unique insights, and when viewed together, correlated on a common timeline, they make it easy to identify the root cause of errors or detect anomalies.
While the three pillars provide observability that facilitates troubleshooting and auditing, there are situations where they come up short:
Data errors – software problems are often caused by erroneous data. Data that’s incomplete or formatted incorrectly can crash a system. In order to troubleshoot an issue, it’s helpful to know where the data was generated, and how it was transformed during its journey to the code it broke. The three pillars make the crash point clear, but it may require a lot of investigative work to follow the trace back to the point where the data originated or became corrupted.
Who’s the root cause…cause? – It’s one thing to discover the point in an application where things went wrong, it’s another to know who wrote the code that caused the error. This is especially true when the cause is code that ran upstream from the code where the symptoms are showing.
For these reasons, we suggest a fourth pillar of observability.
The Fourth Pillar of Observability: Data Lineage
Data lineage refers to the life cycle and journey of your data as it moves from its point of origin, through its various transformations, and finally to its resting place. Data lineage tools like Datorios Data Lineage Analyzer work by recording every change to the data, the code or routine that changed it, and the name of the person responsible for maintaining that code.
Data lineage visibility is critically important for ensuring accuracy and availability of applications, and accelerating troubleshooting, and optimization. Data lineage also plays a vital role by ensuring that data processing meets legal standards in the many industries where regulatory compliance is required. By maintaining a clear record of how data is transformed and moved, companies can provide the necessary transparency to auditors and regulators.
Datorios Data Lineage Analysis
Lineage Analyzer offers a comprehensive suite of features aimed at helping developers trace data across their pipelines, monitor transformations, and identify where data changes occur. Unlike other data lineage tools, which simply display lists of what processes are acting on data, Lineage Analyzer provides insights into the steps within the processes (the data before and after the process) and the relations of events between processes, which makes it clear why data changed. This enables organizations to conduct more thorough auditing, and trouble-shoot with ease.
Datorios provides an x-ray view into real-time processing. By adding a metadata layer to events it enables horizontal and vertical lineage of the data flow along the data pipeline. Key features of Datorios Data Lineage Analyzer include:
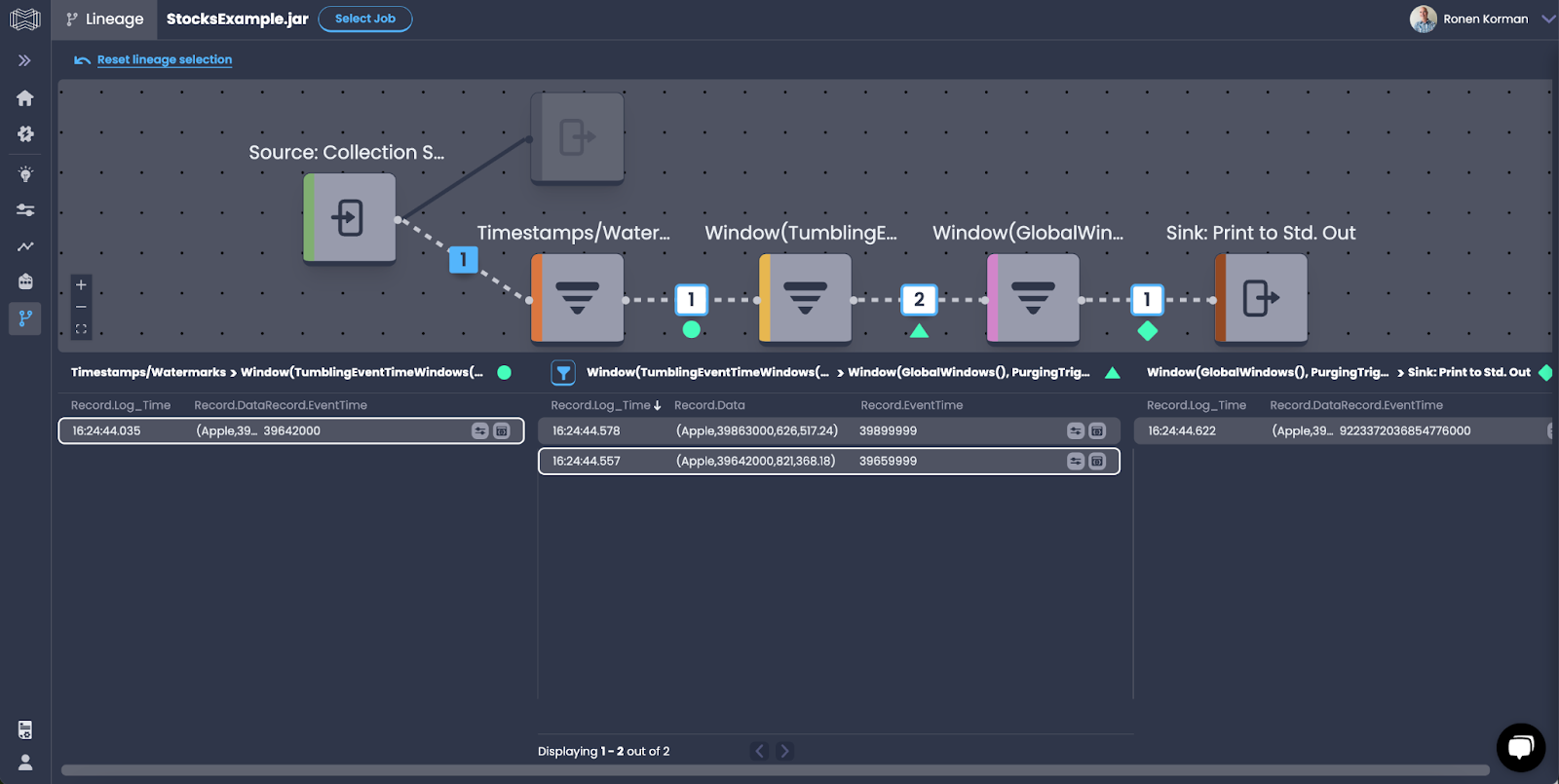
Lineage visualization – View interactive job graphs, which are directed acyclic graphs (DAGs) that provide an overview of the operations that compose your real-time processing pipelines.
Data flow detail – Drill down into job graphs to explore detailed views of data flow operators.
Data tracing – Explore actual data records as they flow through operators, and witness data transformation in real-time.
Limited performance overhead – Unlike other lineage tools, Data Lineage Analyzer runs external to your Apache Flink jobs, which gives you the visibility you need without affecting your real-time system performance.
Quick Guide for Datorios’ Lineage Analyzer
Putting the End to the “Blame Game”
The job graphs contain metadata that includes the names of people who are responsible for maintaining the code. In a crisis, this information helps the team assign the issue to the person who is best able to resolve it. Without this, companies can spend days tracking down the best expert to analyze the root cause and correct it. Datorios helps get the person on the case immediately.
Add Data Lineage Analysis to Your Observability Platform
As trends like AI automation take hold, much is riding on the availability and correctness of real-time data processing and automation. Businesses cannot afford downtime or errors. Observability systems like Datorios are your safety net for real-time business automation. And given the rate at which data moves and changes in real time systems, data lineage analysis is required–as a fourth pillar of observability–by teams who value fast issue resolution and audit compliance.
Whether you’ve recently started your real-time systems development journey or if you’ve been in the game for a while, check out the Datorios Data Lineage Analyzer for Apache Flink. You can try it for free here