In stream processing systems like Apache Flink, state management and checkpoints are vital mechanisms that ensure the accuracy and resilience of real-time data pipelines. They provide fault tolerance, consistency, and allow recovery from failures. However, state and checkpoint analysis often get overlooked until a failure occurs, which can lead to significant disruptions in data processing. By incorporating detailed analysis of state and checkpoints, organizations can maintain high levels of operational continuity, reduce downtime, and improve system performance.
What Are State & Checkpoints in Apache Flink?
State in Apache Flink refers to the data stored by operators while processing a stream. This could be the result of aggregations, joins, or any other computation that needs to keep track of intermediate results over time. Flink’s state is often stored locally on the task managers, and the stateful processing guarantees that stateful computations can continue across events or even recover from failures.
Checkpoints are snapshots of the state of the entire Flink job at a particular point in time. Flink periodically saves these checkpoints to a durable storage system, ensuring that in the event of a failure, the system can restart from the most recent checkpoint without losing data. This mechanism is fundamental for enabling fault tolerance in stateful stream processing.
Despite their importance, state and checkpoint failures are common sources of operational disruptions in real-time data pipelines. However, without proper monitoring and analysis of state and checkpoints, it’s difficult to prevent or resolve these issues before they escalate.
Why State & Checkpoints Analysis Is Crucial in Streaming Data
Fault Tolerance and Recovery The primary purpose of checkpoints in Apache Flink is to ensure that, in the event of a failure, the system can recover to a consistent state without losing data. Analyzing these checkpoints helps ensure that they are happening as expected and that the data is correctly persisted. For instance, if a failure occurs and the checkpoint isn’t correctly captured or is corrupted, the recovery process may fail, leading to data loss or inconsistent processing results.
For example, in a large-scale e-commerce pipeline processing real-time transactions, if a checkpoint fails to capture the right state, the system could restart from an incorrect or incomplete point, leading to inaccurate billing or failed order processing. Regular checkpoint analysis can ensure that the system remains resilient, minimizing recovery time and risk.
Identifying Bottlenecks and Optimizing Performance The process of saving and restoring state can introduce latency into the data pipeline, especially in high-throughput environments. Analyzing the impact of state and checkpoints on performance helps identify bottlenecks, such as long checkpointing times, which can degrade the throughput of the entire system. For example, if Flink is using a distributed checkpointing system, performance might be impacted if the network or storage systems are not optimized for high data volumes.
By analyzing state and checkpoint data, teams can identify which parts of the pipeline are causing delays. For instance, a complex aggregation operation with large state can lead to longer checkpoint times. This allows for targeted optimizations, such as reducing the size of the state, optimizing the network storage used for checkpointing, or increasing the frequency of checkpoint intervals to improve recovery time.
State Size and Resource Management One of the biggest challenges in Flink’s stateful processing is managing the size of the state. As the pipeline processes more data over time, the state size can grow significantly, leading to higher memory consumption and potential out-of-memory errors. State and checkpoint analysis provides visibility into how state grows, how frequently it’s updated, and whether the system is handling the state efficiently.
For example, in an IoT monitoring application, the state size could balloon as more sensors are added. Without proper analysis, this could result in excessive memory usage, leading to failures or degraded performance. State analysis helps optimize memory management, ensuring that the system can scale without running into resource constraints.
Data Consistency and Accuracy In complex pipelines where multiple sources and transformations converge, it is critical to ensure that the state is consistent across all operators. If the state is not synchronized or if some operators miss updates during checkpointing, data accuracy can be compromised. Regular state and checkpoint analysis ensures that state transitions are properly captured, and any inconsistencies can be addressed before they affect downstream processes.
For instance, in financial applications, state inconsistencies can lead to incorrect calculations, such as inaccurate account balances or delayed fraud detection. By consistently monitoring state during processing, businesses can avoid these costly mistakes.
Managing Backpressure and Resource Allocation Backpressure can occur when there is a mismatch between data ingestion and processing capabilities. If the system is unable to process data at the required rate, checkpoints can get delayed, and state can accumulate unnecessarily. This results in a backlog of data, higher memory usage, and longer recovery times in case of a failure.
State and checkpoint analysis can provide insight into how backpressure is affecting the system. By analyzing checkpoint timing and state accumulation, teams can identify when and why backpressure is happening and take action to resolve it, either by scaling the system, optimizing operators, or managing resource allocation better.
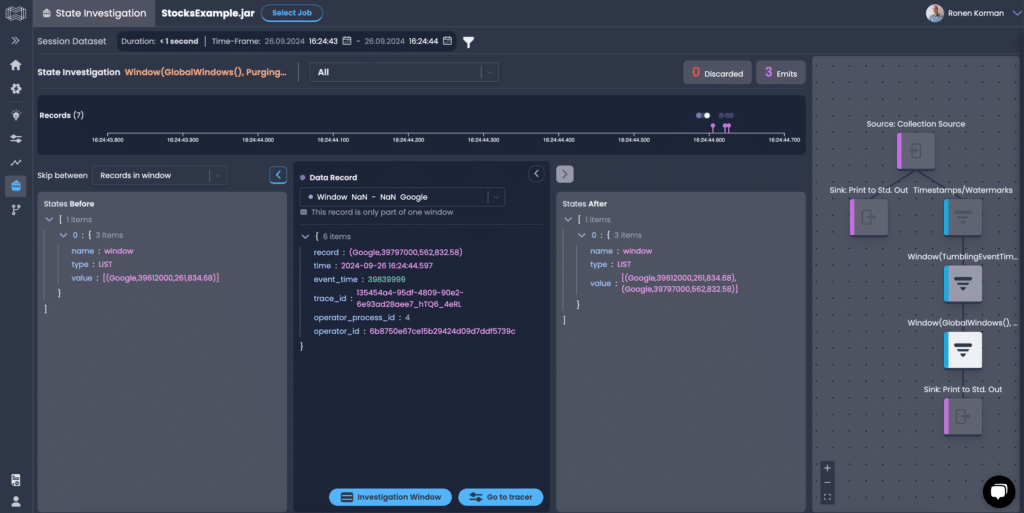
Drill down into each operator to get a fine-grained view into state values & how they were changed
Real-Life Scenarios Where State & Checkpoints Analysis Would Have Helped
Ride-Sharing Platforms and Data Consistency Problems Real-time ride-matching platforms rely heavily on stateful data processing to match riders and drivers, calculate ETAs, and optimize routes. Failures in checkpointing can result in incomplete state recovery after system interruptions. This can lead to incorrect matching, inconsistent ride availability, and delays in trip scheduling. Proactive checkpoint analysis would help these platforms maintain seamless service by ensuring system consistency even during high-traffic periods or failures.
Cloud Service Providers and Streaming Data Pipelines Cloud platforms offering real-time streaming services often face challenges with data processing during system upgrades or recoveries. Misconfigured checkpointing mechanisms can result in data loss or duplication, disrupting service for enterprise clients. Regular state and checkpoint analysis can help cloud providers detect such configuration issues early, minimizing the impact on downstream applications and ensuring reliable service for their users.
Fraud Detection in Financial Transactions Financial systems rely on real-time data analysis to detect fraudulent transactions. Delays or errors in state recovery caused by checkpoint inefficiencies can lead to missed alerts and increased financial risk. Implementing precise checkpoint analysis helps maintain the accuracy and timeliness of fraud detection, reducing false negatives and protecting both institutions and their customers.
E-Commerce and Flash Sale Events During large-scale flash sales or promotional events, e-commerce platforms handle a high volume of real-time transactions and user interactions. Without efficient state and checkpoint management, failures in processing pipelines could lead to cart inaccuracies, dropped transactions, or delayed order confirmations. Regular analysis of checkpoints ensures data consistency and allows platforms to maintain a smooth shopping experience under heavy load.
Logistics and Real-Time Tracking Systems Real-time tracking platforms for logistics and supply chain operations depend on stateful data streams to monitor shipment locations, update delivery times, and optimize routes. Failures in state recovery due to improper checkpointing can cause delays in updates, leading to missed deliveries or inaccurate notifications to customers. Robust state analysis can ensure consistent updates and improve operational efficiency in supply chains.
Streaming Services and User Recommendations Streaming platforms rely on real-time data to deliver personalized content recommendations to users. Errors in state management can lead to outdated or irrelevant suggestions, impacting user satisfaction. For instance, failure to process a user’s recent viewing history due to checkpoint issues could mean the system fails to recommend trending content. With consistent checkpoint monitoring, these platforms can improve personalization accuracy and enhance user engagement.
Telecommunication Networks and Real-Time Analytics Telecom providers use stateful processing for network performance monitoring, call detail records, and fraud detection. Failures in checkpoint recovery can result in delayed analytics, missed performance issues, or undetected fraudulent activity. State and checkpoint analysis ensures continuous and accurate monitoring, improving reliability and security for customers.
How to Implement Effective State & Checkpoints Analysis in Apache Flink
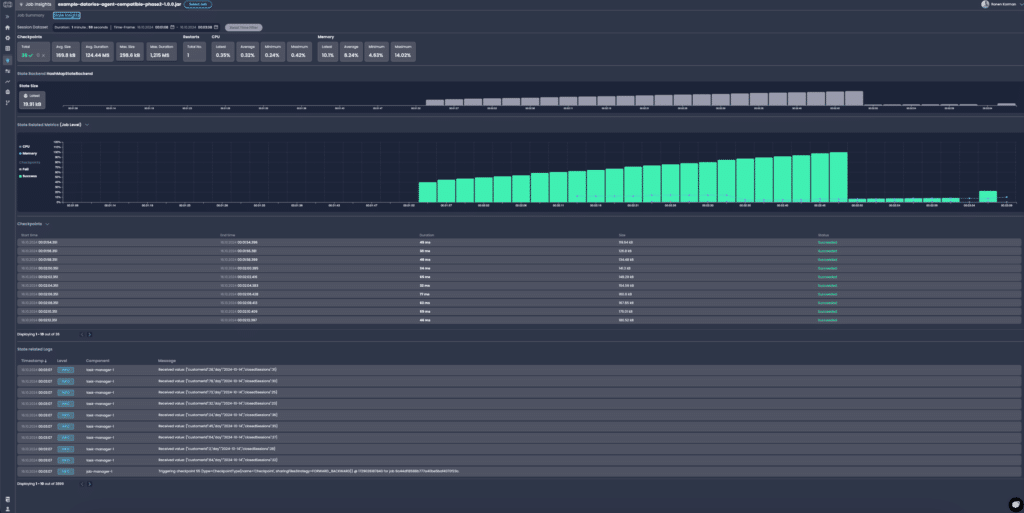
Regular Checkpoint Audits Set up automated tools to monitor and audit checkpoints regularly. This ensures that all checkpoints are successful and that the system can reliably recover in case of failures.
State Size Monitoring Implement monitoring tools that track the size of state over time. This allows you to spot any unexpected growth in state, which could lead to resource strain and longer checkpoint times.
Performance Metrics Integration Integrate Flink with performance monitoring tools to assess the impact of checkpoints on system throughput and latency. Use this data to fine-tune the checkpointing intervals and optimize resource usage.
Failure Simulation and Testing Regularly test the system by simulating failures and reviewing the recovery process. This helps ensure that checkpoints are effective and that the system can resume from a consistent and accurate state.
State Analysis to help understand the overall health of the state held by your operators
Conclusion
State and checkpoint analysis in Apache Flink is crucial for maintaining fault tolerance, data consistency, and system performance. By incorporating these strategies, organizations can enhance the reliability and efficiency of their real-time pipelines. Tools like Datorios can provide deeper insights and visualization capabilities for state and checkpoint analysis, enabling teams to proactively identify issues, optimize processes, and scale operations with confidence.