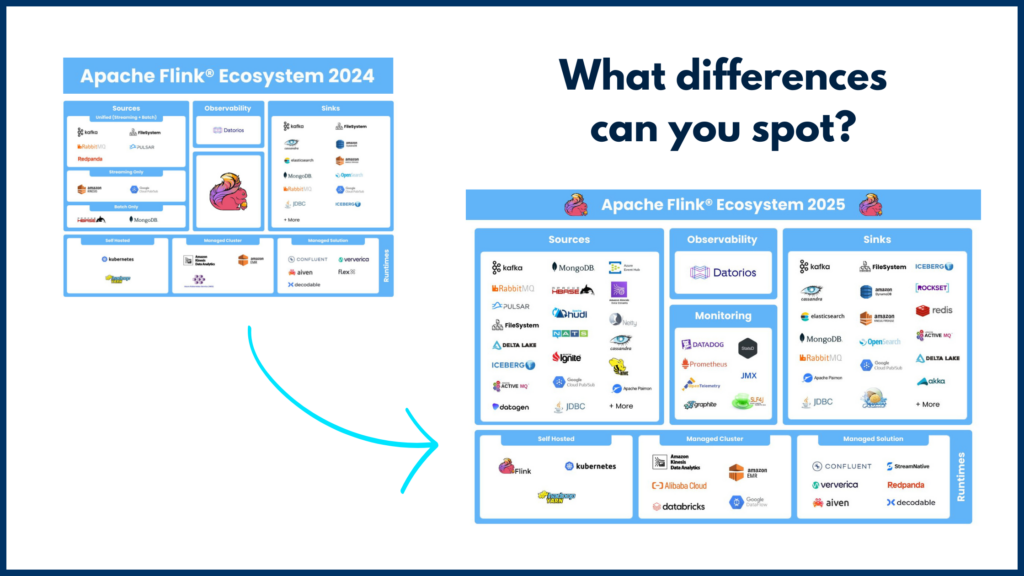
A year ago, we shared a map of the Apache Flink ecosystem, and the response was overwhelming. Developers, architects, and data engineers engaged in discussions about runtimes, observability, and missing integrations – all pointing to a rapidly growing and evolving ecosystem. Today, we’re back with an updated map. the Apache Flink Ecosystem 2025, showcasing the latest advancements and deeper integrations that make Flink the backbone of real-time data processing.
The Apache Flink ecosystem in 2024 compared to 2025
The Apache Flink Ecosystem in 2025 Is More Critical Than Ever
In 2025, real-time data isn’t a luxury – it’s a necessity. Businesses demand faster insights, higher data quality, and more resilient pipelines. As a result, Apache Flink continues to dominate the real-time streaming space, offering more flexibility and scalability across various industries.
Key Highlights of the Apache Flink Ecosystem in 2025:
Sources & Sinks are expanding beyond the usual players, integrating deeply with data lakes and event-driven architectures.
Runtimes are maturing, whether you choose self-hosted, managed, or fully SaaS deployments.
Observability & Monitoring are now central, ensuring real-time data reliability, regulatory compliance, and cost efficiency.
Let’s break it down further.
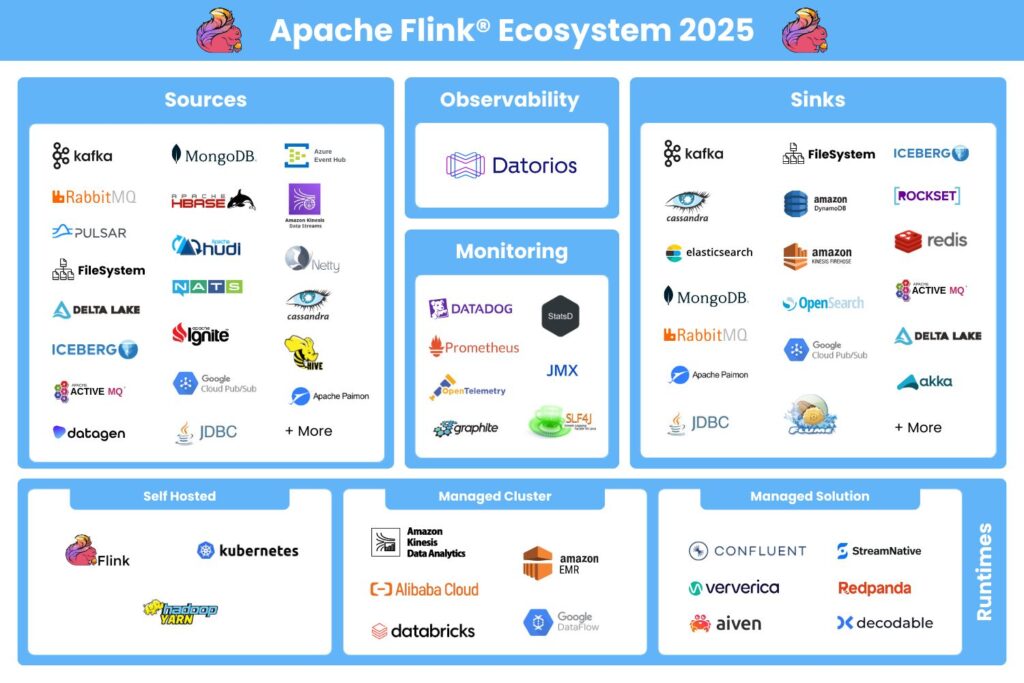
The Apache Flink ecosystem in 2025
Sources: The Streaming Data Landscape is Expanding
With Flink 2.0 on the horizon, everything is moving toward the Source API, creating a more unified ecosystem. Whether batch or streaming, these sources are at the heart of real-time data processing:
Streaming Sources:Kafka, RabbitMQ, Pulsar, Amazon Kinesis, Google Cloud Pub/Sub
Data Lakes & Warehouses: Delta Lake, Apache Iceberg, Apache Hudi, Apache Paimon
More sources mean greater interoperability, making it easier for data teams to ingest and process real-time data at scale.
Sinks: Where Real-Time Insights Land
Once processed, data needs to be stored or further analyzed. The list of Flink sinks continues to grow, ensuring compatibility across different storage solutions and analytics platforms.
Popular sinks:
Message Queues & Streams: Kafka, RabbitMQ
Databases & Data Lakes: MongoDB, Cassandra, Delta Lake, Iceberg, JDBC
Whether it’s real-time analytics, machine learning models, or operational dashboards, Flink’s broad set of sink integrations ensures low-latency, high-throughput data delivery.
Runtimes: How Apache Flink is Deployed in 2025
Apache Flink’s flexibility extends to how it’s deployed. Whether self-hosted or fully managed, companies have multiple options to balance control, cost, and scalability.
Self-Hosted Deployments:
Kubernetes: The preferred orchestration tool for large-scale streaming workloads.
Hadoop YARN: A legacy but still widely used approach for distributed processing.
Managed Cluster Solutions:
Amazon EMR, Google Dataflow, Alibaba Cloud, Databricks – Managed clusters that offload operational complexity.
Fully Managed Solutions:
Confluent, Ververica, StreamNative, Redpanda, Aiven, Decodable – Flink-powered solutions for seamless real-time data processing.
With managed solutions continuing to evolve, startups and enterprises alike can focus on real-time data processing without the overhead of infrastructure management.
Observability & Monitoring: Ensuring Data Quality in Real-Time
As real-time data pipelines grow in complexity, observability is no longer optional – it’s essential. Companies need real-time insights into pipeline performance, bottlenecks, and errors to maintain operational resilience.
Observability:
Datorios – Providing deep insights into event state, time windows, and debugging for Apache Flink applications.
With the rise of regulatory pressures and increasing cost sensitivity, companies are prioritizing real-time data visibility and explainability to make better business decisions.
The Future of Apache Flink: What’s Next?
The Apache Flink ecosystem isn’t just expanding – it’s solidifying its position as the leading real-time data processing engine. Whether you’re building streaming analytics, fraud detection, machine learning pipelines, or financial models, Flink’s deep integrations and ecosystem growth make it the go-to framework for real-time decision-making.
Did We Miss Anything?
This map is our way of capturing the fast-moving world of Apache Flink. If you think we missed an important integration or trend, please let us know.
Stay ahead in real-time data observability with Datorios.